We need to destigmatize feedback in medicine.
Not just to help our learners improve. But also to allow AI to accelerate their development.

In 2003 when I was an R3 I got a 3/5 on the communication component of an in-training evaluation report (ITER) on my internal medicine rotation. I had always done well on the communication sections, so I was a little hurt and spoke to the attending. He cited as an example that I was quite pushy in requesting a lung biopsy in a patient with a peripheral lung nodule. He suggested I should have been more diplomatic in handling this.
I’ve thought about what I did quite a bit. I paged interventional radiology. I paged them again. I called the staff radiologist directly, also twice. I went down to the reading room. I even pulled the elective resident on radiology from his reading to help with the conversation with IR and the techs. When that failed I tried to get the respirology staff to talk to radiology. They said they would expedite an outpatient procedure (these are indeed mainly outpatient procedures). I said it wasn’t good enough - the patient was here, there was time, why don’t we just do it. I was a bit snarky.
Maybe I was advocating for the patient. But I know that I was for sure, in fact, being a jerk.
I could not see that interventional radiology had a list, that my patient was not the only patient on the planet, that the staff radiologist had already weighed the indication and the timing and the risk, that the outpatient biopsy was on a timeline that was perfectly reasonable, just not the timeline I had decided on. And acting as if my one patient should distort the whole queue is its own kind of harm to the other patients I never met. Diplomacy moves the system in a way that pushiness does not. And, the lesson I needed most: I could always, always ask an attending for help. The version of advocacy I was practising was a version where my certainty was the only signal worth weighing.
I am very grateful that I received that feedback.
But that sort of feedback is rare now.
At least at my institution, there is a sort of fear of providing feedback for a few reasons.
It may show up on Dean’s letters and Program Director letters and affect downstream selections for residencies and fellowships. As someone who has scrutinized these on selection committees to stratify degrees of excellence, I can tell you this is a real thing.
There may be retribution to the teacher. Teaching effectiveness scores form part of promotions packages, are the reasons we get teaching awards, etc. Providing honest feedback may result in honest feedback back - which a lot of teachers may not want to receive.
And even further than this - feedback that a trainee disagrees with can come back as a complaint. And time is a precious commodity in medicine - even having to deal with any complaint is a hassle.
So what do we know about feedback, but pretend we don’t
The medical-education literature on feedback is ENORMOUS and the consensus is uncomfortable. I love my colleagues Watling and Ginsburg’s synthesis in Medical Education where they make the point flatly: feedback works when it is heard, and learners only hear feedback when they trust both the relationship and the stakes (they call it the “alchemy of learning” - and I’ve always loved that term). Van der Vleuten and Schuwirth said it even more cleanly in their programmatic-assessment framework: you cannot mix high-stakes and low-stakes assessment in the same instrument and expect either to function. Telio, Ajjawi and Regehr’s “educational alliance” and Sargeant and colleagues’ R2C2 coaching model say the same thing but just in different “vocabularies”.
The moment a piece of data can be used against the trainee, the trainee stops volunteering vulnerable information. The moment a piece of feedback can rebound on the supervisor, the supervisor stops volunteering candid critique. Both directions of the channel collapse at once. What remains is a placid, ironed-out, mild “good job.” We have stigmatized everything else.
There’s a ton of the twist but we’re fresh out of shout.
And often the feedback never gets given in the first place. Faculty have learned to be careful, because written feedback that a trainee disagrees with can come back as a complaint. Trainees have learned to be salesmen - because the sales job that I’m doing a good job is the best thing to avoid the negative data. And both sides know the data is being weaponized. So neither side speaks honestly.
So the thousands of small observations that should make up clinical training - and could improve training - never get said, never get written, and the silence gets coded as kindness.
What I am actually proposing
A piece of feedback should not appear on a resident’s ITER or equivalent rotation evaluation. It should not appear in a Medical Student Performance Evaluation or its Canadian analog. It should not be weighed during resident selection. It should not feed into promotions decisions in residency. It should not be written into a letter of reference for fellowship. Feedback exists for one reason. It exists to make the recipient better. Anything that diverts it toward an evaluator audience corrupts it on the way out.
The right design separates two channels. One channel is summative and evaluative: standardized clinical exams, final EPA entrustment scores, written knowledge tests, and other examinations. Those are the data that decide whether someone advances. They are deliberate, sampled, blinded where possible, and the trainee knows exactly when one is happening.
The other channel is formative: the thousands of small observations a clinical supervisor makes during a shift. The post-procedure debrief. The corridor comment after a tough family meeting. The thing the chief noticed during morning report. The 3 out of 5 written down in good faith. None of these should ever be discoverable by an assessment committee. None should ever appear on a dean’s letter. The trainee should be able to receive them, react to them, log them, ignore them, all without consequence. That is the only condition under which feedback becomes honest. It is also the only condition under which it gets given at all.
This argument did not start with AI
Competence-based medical education (CBME) founding documents simply assumed feedback was being given, and indeed tried to create constructs based on formalizing it. But the blocker in every CBME implementation I have watched (including the gastroenterology program I helped build) is the same.
We cannot get enough rich observations per trainee per year to populate the framework, because each observation is treated as a high-stakes data point. The competence committee at the end of the year is reading tea leaves from twelve sanitized assessments instead of two hundred honest ones.
The fix is not a better form. The fix is to make the formative layer free.
Why the AI era can accelerate real competence in CBME
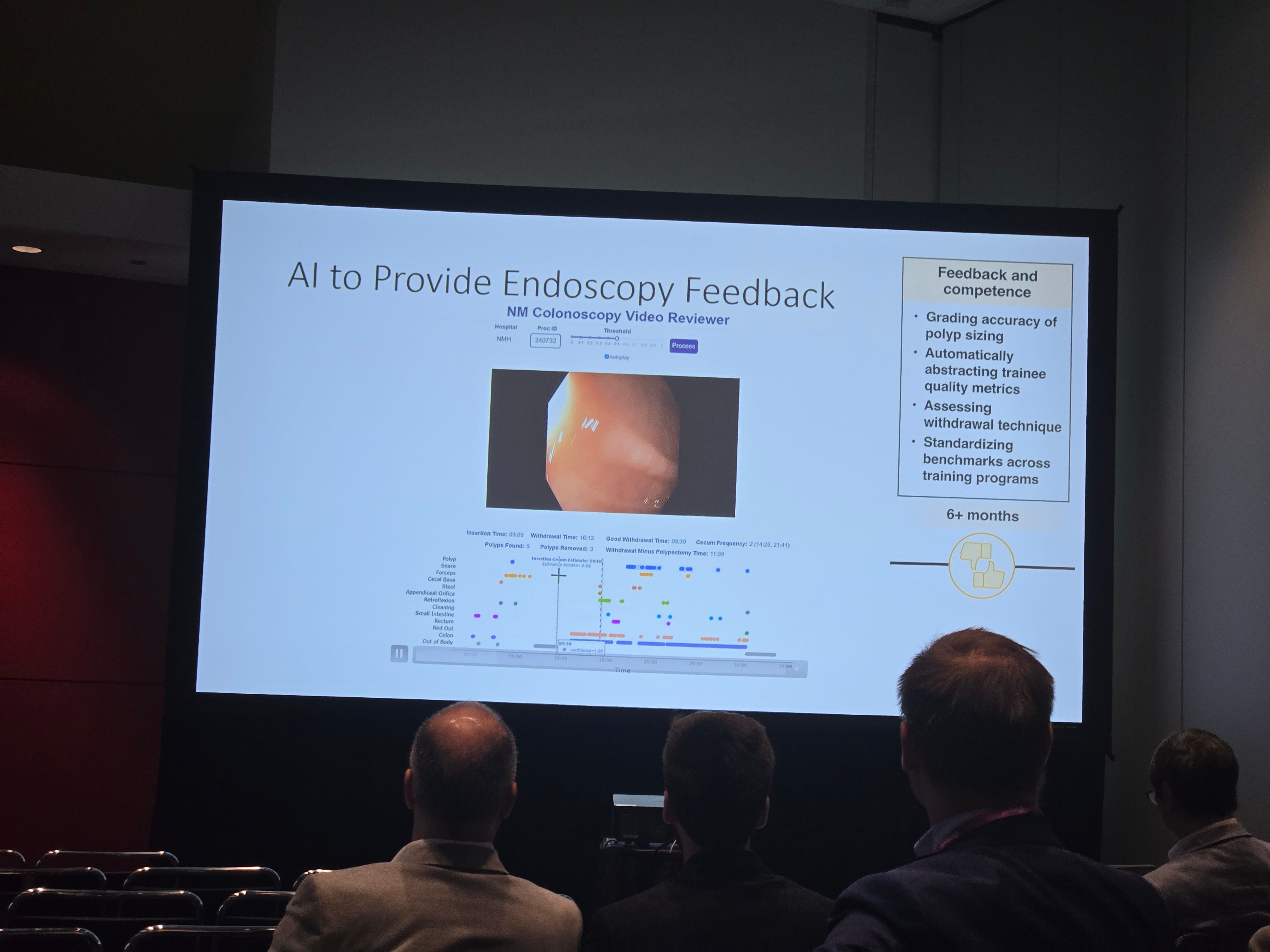
The single biggest constraint on real CBME has always been the cost of observation. You need many independent eyes watching the same trainee across many contexts and many patients. Faculty time is the bottleneck. Faculty also have an incentive to be kind, because their feedback rolls into a stake-bearing form. Both problems are addressable in the AI era.
Ambient AI is already capturing the clinical encounter at scale. Tierney and Lee, writing in Annals of Internal Medicine this spring, made the case that ambient scribes are already redefining what we even mean by documentation quality. That same ambient layer can capture educational signal. The teaching moments, the missed differential, the question the resident asked and the question they should have asked, the procedural step that hesitated, the family conversation that landed and the one that did not. None of this requires more faculty time. It requires the trainee to consent and to trust that the data is theirs.
Pair an ambient observer with the CBME framework and you have something nobody has had before. A continuous stream of low-stakes formative signal, rich enough to populate every EPA, granular enough to coach against, and statistically dense enough that aggregate trends mean something even when any single observation does not. That is what programmatic assessment was always supposed to look like. We could not build it before because human observation does not scale. AI observation scales, and it scales cheaply.
But it only works if the trainee believes the data will not be weaponized.
I have written before, in “I became a good doctor by doing it”, about why the apprenticeship has to be protected from agents that never fumble. This is the same argument’s other half. The data layer of the apprenticeship has to be safe for the apprentice.
The cost of getting this wrong is not that we miss out on a new technology. The cost is that we lock in the world we are already in, where the only feedback anyone is comfortable giving is “good job.” That world produces exactly one kind of mediocre clinician. It is not the one I want my students and residents to become.
It is also not the one whose ITER, in November 2003, said three out of five for communication, and changed how he practised for the next two decades.
