Curriculum as infrastructure: how to keep medical education evergreen

Medicine updates continuously. Guidelines shift, practice patterns evolve, technologies arrive, and expectations move. In my opinion, artificial intelligence really has brought these needs to the forefront; one article from as far back as 2021 suggests that the doubling time for medical knowledge is only 73 days. If curriculum only refreshes every few years, it will always be behind. At that point, the curriculum becomes a historical document, and not a guide to the minimum operating standard for safe medical practice.
If we want an evergreen curriculum, we need to stop treating “updating the curriculum” as a periodic project. It has to be a standing capability.
The real question for defining a curriculum is not, “What should we teach?” It is: “What is our process for continuously deciding what counts as competence, and continuously aligning teaching and assessment to that decision?”
That is a core shift in my opinion. The process is what is critical to curriculum.
What “curriculum” should look like - as a system
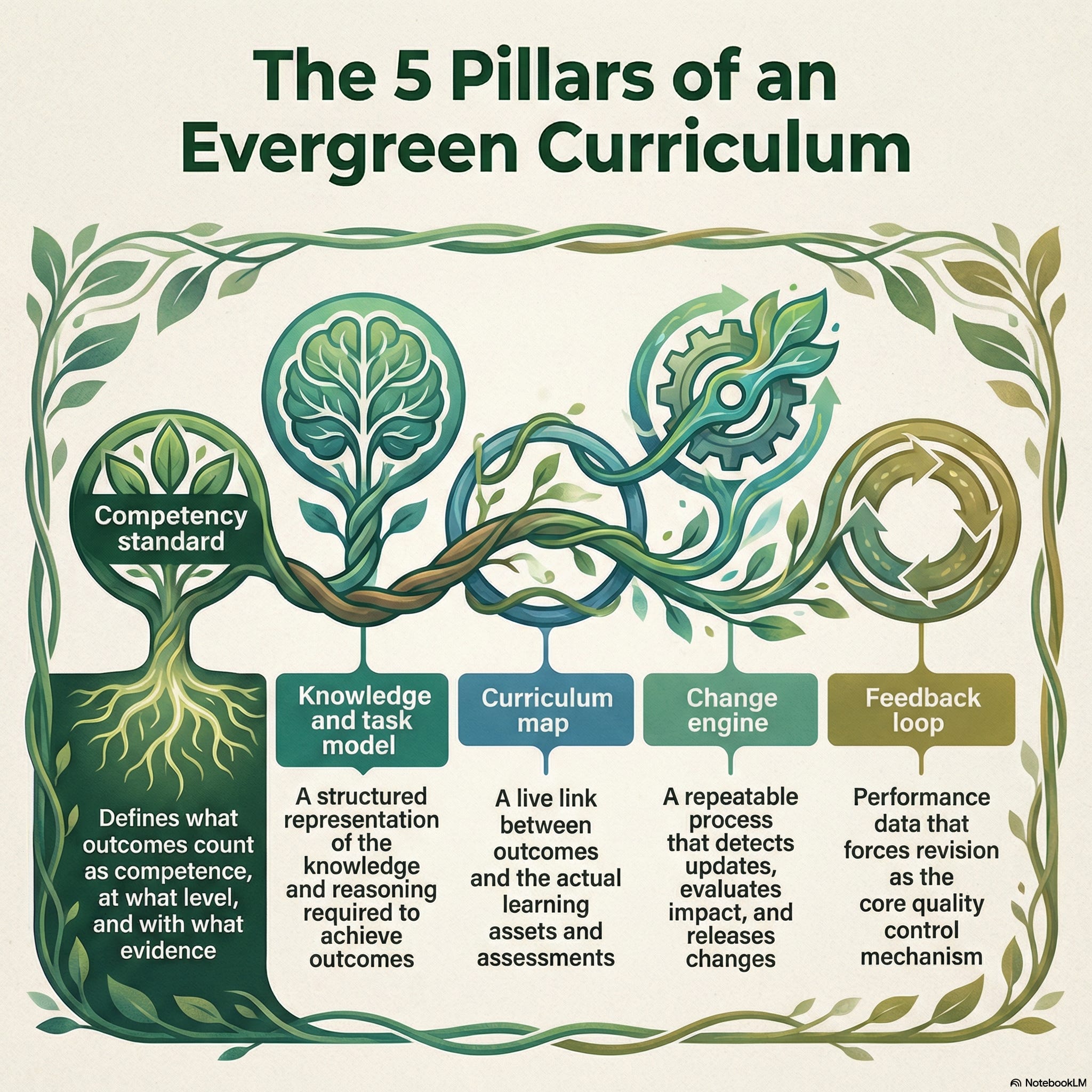
An evergreen curriculum is a pipeline with five components that run all year:
Competency standard
What outcomes count as competence, at what level, and with what evidence.Knowledge and task model
A structured representation of the knowledge, clinical work, and reasoning patterns required to achieve those outcomes.Curriculum map
A live link between outcomes and actual learning assets and assessments. This needs to be living and breathing and modifiable with ease.Change engine
A repeatable process that detects updates in medicine (e.g. new clinical practice guidelines), evaluates impact, and releases changes to the competency standard and map. This can be AI driven but needs humans in the loop (e.g. a curriculum committee)Feedback loop
Performance data that forces revision, not as an afterthought but as the core quality control mechanism. The ideal state on this is patient outcome change, but outcomes of less impact, such as improved patient care outcomes may be easier to achieve states (see this excellent review by McGahie and colleagues from Northwestern on this framework in simulation).
Most institutions definitely have parts of this - but the full CQI integration is still not all there IMO. Here is the NotebookLM generated infographic
Systems that already exist (and what they teach us)
1) Versioned competencies that are explicitly revised
One strong recent example is the new Foundational Competencies for Undergraduate Medical Education, co-sponsored by AAMC, AACOM, and ACGME. The project page documents an iterative pathway: an initial draft circulated in January 2024, a second draft circulated in April 2024 with community input collected through May 10, 2024, then further review before final publication in December 2024.
This is a process we should emulate: explicit versioning, explicit method, and explicit update history.
Another practical example is the AAMC’s Quality Improvement and Patient Safety (QIPS) Competencies Across the Learning Continuum, Version 2 (September 2024). The AAMC describes an iterative revision process that began in September 2022, included a literature review, discussion of each competency, and a public feedback process, culminating in a versioned update aligned to current evidence and priorities.
Even if you disagree with specific competency wording, the process is the point. Competency standards can be maintained, and the maintenance process can be transparent.
2) Curriculum mapping but as active surveillance, not just documentation
Curriculum mapping is one of the few tools that can show drift. It shows what is taught, where, how often, and what is assessed.
A 2025 BMC Medical Education paper describes identifying a curricular gap via mapping, then filling it using a Theory of Change approach to create a structured framework and process for revision.
Where this becomes feasible at scale is when mapping is active and AI-assisted.
A useful way to think about it is “continuous tagging”:
Every new lecture, case, video, simulation, policy, etc. gets tagged at creation to the competency standard and to the knowledge, task model, location in curriculum and location of delivery.
Every new assessment item gets tagged the same way.
Dashboards allow near real time views of gaps, redundancy, and misalignment.
Updates to competencies automatically trigger an “impact list” of mapped assets and items that require review → this can then go to humans-in-the-loop for action.
Example:
Grover makes a simulation on breaking bad news of colon cancer as part of endoscopic simulation of “non-technical skills” for the PGY2 general surgery endoscopic simulation curriculum.
LLM tags it to the relevant CBME competencies/EPAs; to process of simulation-based learning; to process as mastery learning; and to the “tree of knowledge”.
Dashboard identifies that breaking bad news is already taught in the General Surgery academic half day, and is a transferable skill from clinical skills from UG. But trainee feedback has identified it as an area of further training.
Curriculum committee reviews and decides that application of this simulation to an immediate post procedural scenario is additive to breaking bad news training.
LLMs can materially reduce the workload here, but only if they are used as an acceleration layer, not an authority. Raskob and colleagues describe how AI, including LLMs, can enhance the efficiency and creativity of curriculum mapping, while emphasizing the limitations and boundaries of these tools.
3) Accreditation as a “forcing” function
Accreditation expects CQI. A 2024 scoping review specifically examines the relationship between accreditation and CQI in undergraduate medical education, highlighting that evidence on accreditation’s effect on CQI is still emerging, and that institutions often need to strengthen the culture and systems that turn accreditation into sustained improvement.
Accreditation can consequently be a strong lever. If an institution already has CQI structures attached to accreditation — the opportunity exists to connect them tightly to competency updating and curriculum mapping, instead of running them as parallel bureaucracies.
Why RAG matters, and what it changes
AI is not valuable here because it can “write curriculum.” It is valuable because it can scale the boring work, if it is constrained correctly.
General-purpose language models have predictable problems in high-stakes settings: hallucination, outdated internal knowledge, and weak traceability. A 2025 systematic survey of retrieval-augmented generation (RAG) for education highlights these as core challenges, and frames RAG as a way to improve reliability by grounding generation in an external knowledge base rather than the model’s internal memory. I talk about it a little in my last article also.
For curriculum evergreening, I am bullish on RAG being the architecture:
Index approved curriculum assets (slides, nots, syllabi, cases, policies, videos, readings, assessment blueprints - in multimedia format).
Retrieve the most relevant assets for any query, update trigger, or mapping request.
Generate an answer, a mapping suggestion, or a draft assessment item that is explicitly grounded in the retrieved materials.
Cite sources so humans can verify.
This creates a practical capability: you can ask, “Where do we teach and assess extramedullary hematopoiesis?” and get a traceable answer grounded in your own materials. More importantly, you can ask, “If we competency X changes, what downstream assets and assessments are affected?” and get a first-pass impact analysis on what the program needs to change.
The Yale example: curriculum search as infrastructure
Yale’s “Curriculum Search” is the clearest illustration I have seen of how RAG can be turned into a real institutional tool.
According to Yale School of Medicine’s October 24, 2025 write-up, Curriculum Search uses a multimodal LLM plus a RAG system to search thousands of files and answer questions about the MD curriculum using materials such as lecture notes, presentations, and syllabi.
Several specifics are worth emphasizing because they map directly to what an evergreen pipeline requires:
Gated sources: Yale distinguishes Curriculum Search from general AI tools by using RAG “gates” that restrict what sources the AI can consult, and the tool can only provide answers related to MD curriculum materials it consults (so hallucination based on extra-curricular sources is minimized).
Operational validation: Early access was granted to 15 faculty and select staff; they ran controlled queries, compared outputs against source materials, and the team adjusted parameters based on observed gaps and inconsistencies.
Source transparency as a design requirement: Faculty requested to see where information came from, and Yale added a citation list with links to lecture notes, slides, labs, or readings.
Explicit update cadence: Yale notes that the tool initially searches documents from the 2024 academic year, and in the future content will update twice a year, in January and July. That last point is the “evergreen” concept made concrete. Updating is not aspirational. It is scheduled.
Yale also articulates the downstream value: mapping curriculum to competencies, generating high-quality multiple-choice questions linked to course materials, and helping students find where topics are covered.
This is in my opinion the most developed workflow that is in use currently in undergraduate medical education for real continuous curricular improvement.
What institutions should do now
If you want a curriculum that updates continuously, build the pipeline and run it like operations.
1) Establish a versioned competency standard
Adopt or align to external validated standards where possible.
Publish a local competency specification with versioning, changelogs, and deprecation rules.
Define a review cadence and an urgent update pathway.
2) Build a knowledge and task graph
Think of this as the “wiring diagram” under the curriculum. It is the structured map of clinical work and reasoning, not a lecture list. The point is not academic elegance, it is change control. When medicine changes, you can see what is affected. This will need some research to iterate and develop - again AI can help with this.
3) Make curriculum mapping continuous
Require tagging of every new learning asset and every new assessment item to competencies and to the graph.
Run audits that surface gaps, redundancy, and misalignment.
Use structured revision methods when gaps are found
4) Adopt and populate RAG for content
Index only approved materials (e.g. curriculum committee/HITL reviews)
Require citations on every output.
Use AI to propose mappings, surface gaps, and draft assessment items, then have humans adjudicate.
5) Close the loop through assessment and the LMS
This is where “continuous updating” becomes real. If assessment is mapped to competencies and the graph, then changes in competencies force changes in assessment blueprints, and learner performance data becomes a quality signal that triggers revision. Lots of research needed on this. Our lab is looking at frameworks for this as a start.
Could this be global?
The million dollar question. Could this not be one process for all. While a single universal content package is unlikely to be appropriate (context matters, and practice environments differ, etc.)… what could be plausible is a global reference implementation of the evergreening process: shared competency models, shared graph conventions, shared RAG-based tooling, and transparent change logs. Then local institutions adapt “overlays” for regional variation, scope of practice, resourcing needs, etc.
I’d love to chat more about this. Please do feel free to comment or shoot me a message.
